In-Memory Key-Value Store with Concurrency Support
The code written and used for this project can be found here.
Process
For this project, we designed and implemented an in-memory key-value store that supports concurrent operations, ensuring data consistency and efficiency. I selected a hash map as my baseline structure since it has efficient lookup times. I allowed for 100000 values to prevent the dataset from being too small and inaccurately reflecting the performance of my dictionary (disregarding the value size). The data values I used are randomly generated using my generateTestData() function, which randomly selects characters from a given character set of alphanumeric characters with customizable string length. This results in my outputs having some variation in performance. I started by encoding my dictionary, allowing for dynamic/user-specified thread count.
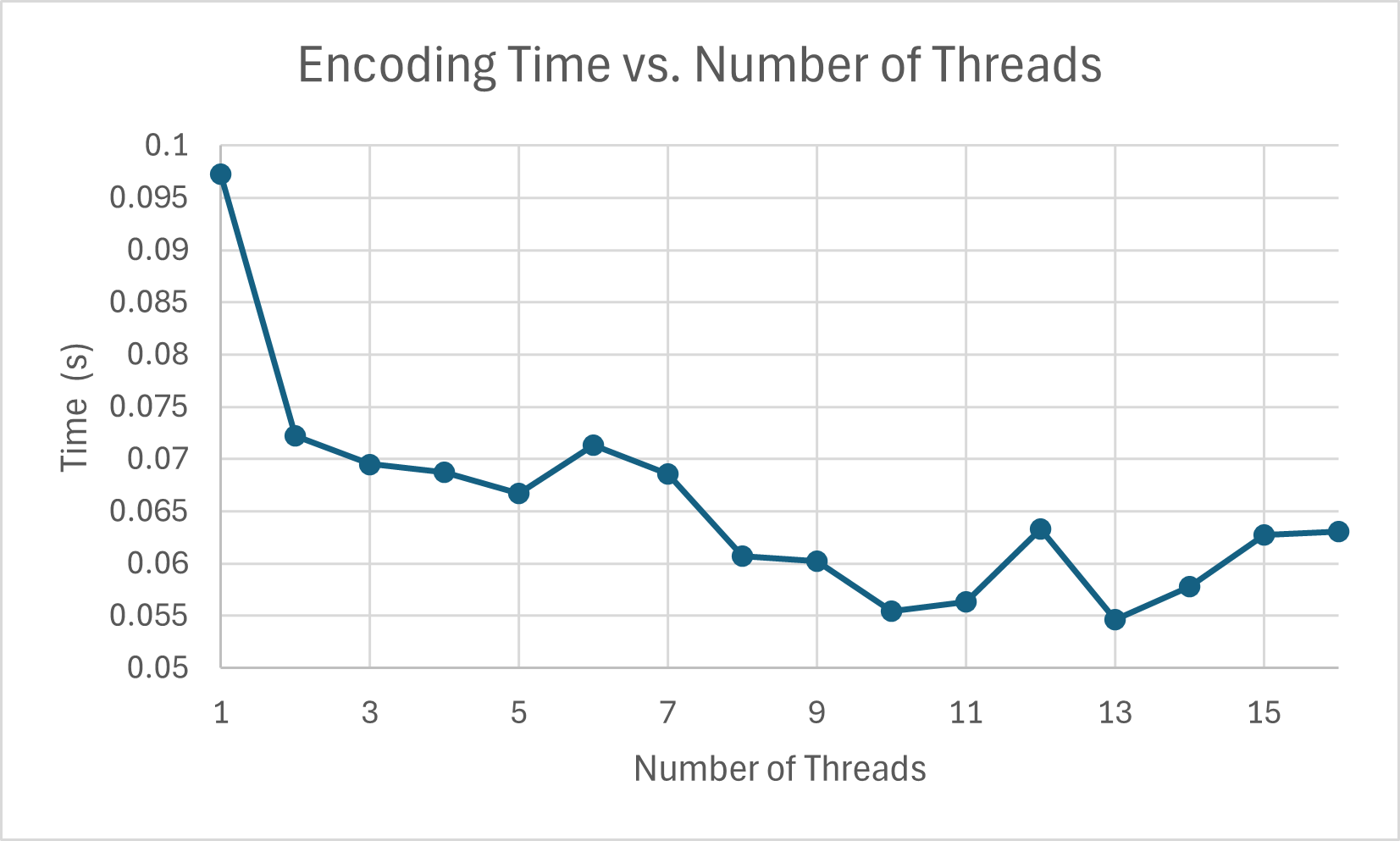
As a general trend, we see that there is a consistent increase in speed between 1 thread and 5 threads. However, beyond that, there isn’t a consistent increase in speed. This can be attributed to the overhead of thread management (e.g. write conflicts). From this, I settled on using 4 threads for subsequent testing. Then, I compared encoding time between different value sizes (keeping key size at 8B):
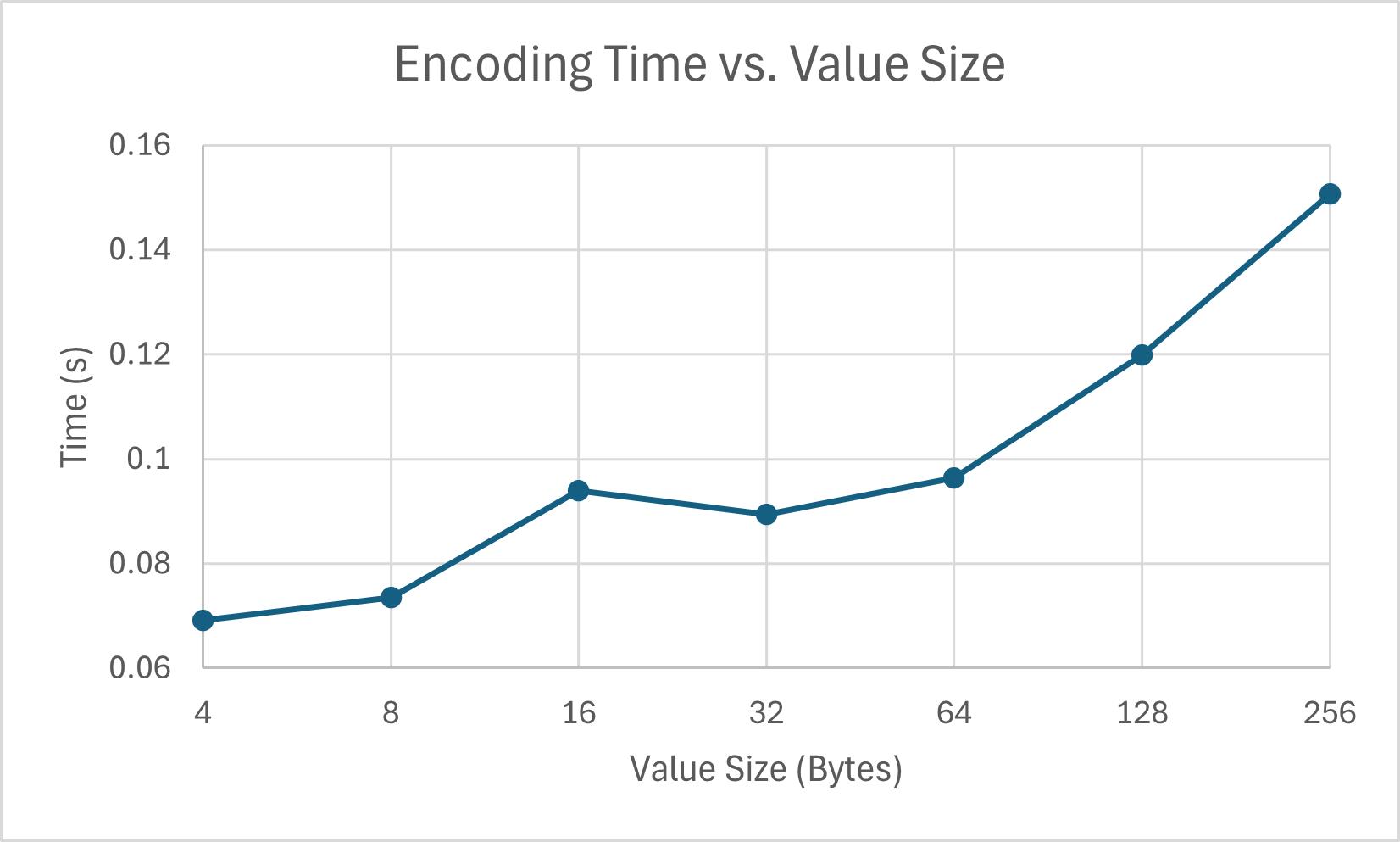
Despite there being a slight uptick at 16 bits, we see there is an approximate almost-quadratic sloping to the relationship between the two variables. Regardless, encoding time and value size have a positive correlation. I settled on 8 bits for value size for subsequent testing to ensure reasonable execution time. z
The next step was comparing the different Query methods:
- Vanilla Column Scan for baseline comparison
- Non-SIMD, Dictionary-Assisted Lookup
- SIMD with Dictionary-Assisted Lookup
Starting with single value querying, one run of my results were as follows:
Vanilla Querying "AOchoypD" took 0.000793744 seconds.
Non-SIMD Querying "AOchoypD" took 0.000552294 seconds.
SIMD Querying "AOchoypD" took 2.8455e-05 seconds.
SIMD is clearly fastest, which is as expected. Non-SIMD is second fastest, taking advantage of the fast lookup time provided by the underlying unordered_map structure I used. The slowest method was the vanilla column scan. To prevent randomness from skewing these results on various runs and to help with easy verification, I fixed the value we looked for to be the center value of the dataset (dataset[50000]). Then, I tried implementing the prefix querying for an arbitrary prefix “a”, which gave me the following timings:
Vanilla Querying prefix "a" took 0.000934774 seconds.
Non-SIMD Querying prefix "a" took 0.502999 seconds. // direct implementation w/ nested loop
Non-SIMD Querying prefix "a" took 0.0125862 seconds. // optimized implementation
SIMD Querying prefix "a" took 0.080746 seconds.
At first I was quite perplexed as to why the vanilla method was so much faster, but I realized it lacked the multi-value decoding step required of the other two methods. Without the second decoding step, the Non-SIMD and SIMD methods only took 0.00635027 seconds and 0.00599924 seconds, respectively. For Non-SIMD, despite the direct implementation being significantly slower, I was able to optimize it by precomputing all the matching dictionary indices, then collecting matching indices via a single pass over the encoded columns. This ended up being faster than the SIMD Querying method which, despite spending multiple hours trying to optimize it further, I could not improve the runtime any further. This is likely due to the overhead of SIMD Setup. Further SIMD usage would require more nested loops, which would actually worsen the overall performance. One potential solution that can be considered that I did not try is splitting up the storage of the dictionary into sections to allow multithreading for parallel prefix querying isolated in sections of the dictionary, then merging the results. Additionally, I did not try other prefixes, so performance may vary for longer prefixes.
Lastly, I checked the performance across different operational concurrencies (varying the different queries with a mod 4 calculation). Each user performed 5000 operations.
Operational concurrency with 1 users took 11.2202 seconds.
Operational concurrency with 2 users took 11.7106 seconds.
Operational concurrency with 4 users took 12.6715 seconds.
Operational concurrency with 8 users took 15.4998 seconds.
As expected, the more users, the longer the overall execution time. This is due to needing to wait for the shared mutex for the dictionary to be released before other users can access it.
Citations
ChatGPT & Claude.ai used liberally for all parts.